Python Corner
(NB: Leopard 上の Python-2.5 に基いた、新しいページを書きかけています。)
目次
GPIB を Python で制御する CGI スクリプトと日本語 数値計算とプロット
最新モジュール・アプリケーション一覧 (3/27/05)
- x Python-2.3.4 (5/28/04)
- x Python-2.4b1 (10/23/04) ⇒ 10/23/04 のオタク日記
- x Python-2.4 (12/22/04)
- x Python-2.4.1c1 (3/12/04) ⇒ 「Install 録 (3/12/05)」
- x Python-2.4.1c2 (3/21/04)
- x Python-2.4.1 (4/2/04)
- Python-2.4.2 (10/3/05)

- x JapaneseCodecs-1.4.10 (4/25/04) (10/23/04 使わなくなりました。)
- PIL: Imaging-1.1.4
- x Numeric-23.5 (9/28/04)
- x Numeric-23.7 (2/5/05) ⇒ 2/5/05 のオタク日記
- Numeric-24.0 (4/19/05)
⇒ 「インストールメモ (4/19/05)」
- x Numarray-1.0 (7/4/04) ⇒ 7/4/04 のオタク日記
- x Numarray-1.1 (9/11/04)
- x Numarray-1.1.1 (12/22/04)
- Numarray-1.2.3 (3/12/04)
- gnuplot-py-1.7 (4/25/04)
- gnuplot-4.0.0 (4/21/04)
- x mailman-2.1.5 (5/22/04) ⇒ 5/22/04 のオタク日記
- mailman-2.1.6b4 (3/12/05)
⇒ 「インストールメモ (3/12/05)」
- + spambayes-1.0 (10/2/04) ⇒ 環境自慢「迷惑メールを撃退する」
- + spambayes-1.0.4 (3/27/04)
⇒ 「インストールメモ (3/27/05)」
- linux_gpib-3.1.101 (3/12/05)
⇒ 「GPIB を Python から使う」
インストールメモ (4/19/05)
Numeric-24.0 にアップデート。デフォルトでは atlas ライブラリに依存していないようで、23.x で必要だった setup.py の変更は必要ないようです。必要とあらば customize.py で参照できるようになっている。インストールメモ (3/27/05)
spambayes-1.0.4 を、デスクトップ機 (旧サーバ) と ThinkPad X22 (新サーバ) にインストール。前者は 1.0 からのアップデートで、何の問題も無く動いた。 ThinkPad へは新規のインストールでしたが、これがちょっと驚きの結果に。 まず、トレーニング無しの状態でフィルタを通すと、 X-Spambayes-Classification が、unsure; 0.50 になる。これは、README と食い違っていますが 1.0 の時からこうなってるようです。しかし、旧サーバの spam や ham のデータを使って一回だけトレーニングしたところ、全てのメールを spam (しかも score が 0.99 や 1.00 ばかり) としてしまう事を発見。 というか、半日くらい一通も ham が届かないので、おかしいと思って spam 溜めを見た訳。 すっかり焦ってしまい、旧サーバの .hammiedb をそのまま持ってきて sb_filter.py を試すと、ちゃんと動いている。 一旦それを消して、またトレーニングしてみたが、それもちゃんと動く。 要するに、問題が再現できないので、 最初のトレーニングの操作ミスの線が濃厚ですが、トレーニングは crontab のファイルから command line への copy & paste で行なっているので、タイプミスは無いと思うんですが…。何故だろう。 気味が悪い。しばらくは、スパム溜めをよく見ていよう。インストールメモ (3/12/05)
mailman-2.1.5 の daemon 群をターミナルから起動してみて解ったのですが、どうも Python を 2.4 にしたころから、
.....
File "/usr/local/mailman/Mailman/Bouncer.py", line 131, in registerBounce
time.strftime('%d-%b-%Y', day + (0,)*6))
ValueError: day of year out of range
なんて error message が出るようになっていたみたいです。
配送そのものにはなんら問題ありませんでしたが。(0,)*6
を足しているところを、(0,0,0,0,1,0) とする事で ValueError
は回避できるようになりました。うーん、これは Python-2.4
としてはあらずもがなの仕様変更じゃないかなぁ。Mailman-2.1.6b4
では、(0,0,0,0,1,0) が足されるようになっています。(mmjp-users
で菊地さんに教えていただきました。)
GPIB を Python から使う
3/12/05 作成
はじめに
思うに、自動測定 (一般に機器制御) は、Python が最も本領を発揮する分野ではないでしょうか。 第一に、Python は徹底して「動的 (dynamic)」 な言語なので、このような用途において不可欠なカット・アンド・ トライを極めて容易にします。 例えば、 マニュアルにある機器制御コマンドが本当はどのような動きをするのか、 コーディングする前にちょっと確かめたい、 という事がよくあります。 (実はこれ、マニュアルがよく整備されたメーカの製品でさえ日常茶飯事で、 「マニュアルなぞは形だけ」といったベンダさんの製品と付き合うのなら、 これなくしては、そもそもプログラムに取り掛れない:-p)
第二に、Object Oriented なので、対話的な操作を種々のレベルで実行できます。 例えば、IFC (Interface Clear) に対する応答やデリミタ確かめて接続が確認できたら、 以後はその機器を模したオブジェクトを作って、 それとのコマンドやデータのやりとりに専念する。 さらには、そのコマンドを使ったさらに抽象的 (高水準) な操作、 例えば周波数の設定などを、 対象となる機種に独立なメソッドとして実装するなど。 これらが全て、対話的に実行できます。
具体的にどんな感じになるか (できるか)、というと
>>> import PyGPIB
# アドレス "1" にあるネットワークアナライザのオブジェクトを作る
>>> na = PyGPIB.gpib(1, "NA, E5071E")
>>> na.IFC() # IFC を送ってみる
>>> na.REN() # REN (Remote ENable を送ってみる
# ここまでで、Python の側にエラーが出ず、測定器も文句を
# 言わなければ、H/W (とその相性) は基本的に OK だろう。
>>> na.puts("*IDN?") # Identification を要求する
>>> na.gets()
>>> 'Agilent Technologies,E5071B,MY4230xxxx,A.03.xx\n'
# と、ここまでくれば、デリミタの互換性の問題はクリアで
# きていて、文字列のやりとりは OK。
>>> na.puts(":SENS1:FREQ:START 1E+9") # sweep start の設定
>>> na.puts(":SENS1:FREQ:START?") # 確認してみる
>>> na.gets()
>>> '+1.0000000000E+009\n'
# 測定器のパネルを見ながら以上をやってみて、このコマンド
# が、意図どおりのものかどうかが確認できる。
>>> na.set_freq_range(1E+9, 2E+9)
>>> na.get_freq_range()
>>> '+1.0000000000E+009, +2.0000000000E+009\n'
最後の例は、仮のもので、
例えば上のコマンドを使ってこのような抽象化したメソッドを作っておくと、
マニュアルと首っ引きでなくても、対話的に測定器を制御できそうです。
勿論、そのメソッドが具体的にどのような GPIB コマンドを出すかは、
最初にオブジェクトを生成した時に与えた機器のモデル名に応じて override
する訳です。
「仮」とは言え、Tektronix の ET488 というアダプタをを使った環境で、実際にこれに近い事をやっていました。 大変便利に使えていたので、最近、また自動測定の環境が必要になった際は、 この環境を再度作れないか、という事から始めたのでした。 しかしながら、このアダプタはもう生産されていず、 後継機も出ていません。
ET488 そのものでなくても、そのアダプタの PC 側の I/F が Ethernet であれば、Python では Socket モジュールを使ったプログラミングになるので、 以前作ったスクリプトの手直しで済むのですが、 残念ながらそういうアダプタは見付かりませんでした。 たまたま手許に有ったのは、NI (National Instruments) の PCM-CIA カード (その名も "PCMCIA-GPIB"。まんまですね)。NI の他のタイプのアダプタは Linux のドライバが有るのに、このタイプにはまだ無いそうで、 「残念」と思ったのですが、 なんとかならんか、とインターネットを徘徊しているうちに linux-gpib という Linux アプリケーションに出会えたのでした。 なんと、これは Python や Perl のスクリプトから使うためのモジュールも含んでいて、まさに「怪我の功名」。 結局 Python から使うためには最も近道だったようです。
Linux-gpib のインストール
ThinkPad X22 の FC-1 (kernel-2.4.22-...) で使うので、linux-gpib は 3.1 の枝を使います。 ソースは sourceforge.netにあります。1/21 の時点での最新版は、 linux-gpib-3.1.101 でした。
例によって、ドキュメント (この場合は、トップディレクトリの INSTALL) を良く読まずに始めてしまったのですが、 今回はあまりツキに恵まれず:-p 結構右往左往しました。 肝は kernel ソースの ".config" ファイルを作るところ。 デバイス・ドライバや VMware のコンパイルでも同様の事をやったので、特に改めてやる事もないだろう、 などと思ったのが大間違い。展開したソースツリーの home にある Makefile の EXTRAVERSION をちゃんと直さないとだめでした。 ("-1.2199nptlcustom" から custom を取る。 それにしても、なんでこんなデフォルトになってるんだ?)
もうひとつのハードルは、gcc のバージョン。FC-1 のカーネルは、gcc-3.2 でコンパイルされているのに、FC-1 の標準の gcc は 3.3。今までは、この違いが問題になった事はなかった (VMware のインストール時に警告はされますが、まあ、実際上問題は無かった) のですが、linux-gpib では違っているとダメです。 ここは、カーネルを弄るのではなくて、linux-gpib を CC=gcc32 としてコンパイルします。(勿論 gcc-3.2.x がインストールされている必要があります。)
linux-gpib のソースに添付の INSTALL を若干訂正してステップ・バイ・ステップ風に書くと、
- カーネルソースの展開、コンパイル。
展開する場所は、一般ユーザが write permission
を持っているところにした方が簡単、とありますが、
私のところでは、今有るソースツリーの他に場所を探す方が大変だったので、
/usr/src/ の下のツリーを再利用しました。後で、linux-gpib を
configure する時、sudo する必要がありますが、それでも問題は無さそう。
ソースツリーのトップで、上の注意の通りに Make を編集してから、
make oldconfig; make dep とやる。
- Linux-gpib をコンパイルしてインストール
Linux-gpib のソースツリーのトップで、./configure --enable-pcmcia を実行。ついで、 make CC=gcc32, #make install
- etc/pcmcia の下のファイルを全て、/etc/pcmcia に copy する。
- 自分 (linux-gpib を使う人) を、gpib グループの一員にする。
usermod を使っても良いけど、/etc/passwd を編集した方が早い?
- /etc/gpib.conf を編集する。結構ごちゃごちゃしているけど、
実はさほど大変ではない (と思う)。
頑張ってバイナリデータをがんがんやりとりしたい人は別にして、
まず、
- 原則としてキャラクタデータに限定する。
- secondary address は使わない。
- DMA は使わない。
- 送信側のデリミタは、'\n' とし、最後のバイトに EOI を付ける。
- 受信側は、'\n' をデリミタとする ('\n'
を受信した時点で、受信動作をやめる)。
- 原則としてキャラクタデータに限定する。
- /etc/rc.d/init.d/pcmcia restart として、cardmgr をリスタート。
Linux-gpib を使ってみる
例えば、GPIB address = 17 に Network Analyzer, address = 3 にアンテナ回転台のコントローラを継いだとします。 この場合、/etc/gpib.conf は、
interface {
minor = 0
board_type = "ni_pcmcia_accel"
name = "NI"
pad = 0 /* primary address of interface */
sad = 0 /* secondary address of interface */
timeout = T3s /* timeout for commands */
eos = 0x0a /* EOS Byte, 0xa is newline */
set-reos = yes /* Terminate read if EOS */
set-bin = no /* Compare EOS 8-bit */
set-xeos = no /* Assert EOI whenever EOS byte is sent */
set-eot = yes /* Assert EOI with last byte on writes */
/* settings for boards that lack plug-n-play capability */
base = 0 /* Base io ADDRESS */
irq = 0 /* Interrupt request level */
dma = 0 /* DMA channel (zero disables) */
master = yes /* interface board is system controller */
}
device {
minor = 0
name = "Network Analyzer" /* device mnemonic */
pad = 17 /* The Primary Address */
sad = 0 /* Secondary Address */
eos = 0xa /* EOS Byte */
set-reos = no /* Terminate read if EOS */
set-bin = no /* Compare EOS 8-bit */
}
device {
minor = 0
name = "Rotator" /* device mnemonic */
pad = 3 /* The Primary Address */
sad = 0 /* Secondary Address */
eos = 0xa /* EOS Byte */
set-reos = no /* Terminate read if EOS */
set-bin = no /* Compare EOS 8-bit */
}
沢山ついているコメントで殆ど自明だと思われますが、board_type
だけは、("ni_pcmcia" ではなく) "ni_pcmcia_accel"
でないと動きませんでした。
こうしておいて、各機器の電源を入れてから、 インターフェースカードを挿すと、早速次のように Python から操作が可能になります。
>>> import Gpib
# GPIB で繋がった機器に対応するオブジェクトを生成する
>>> na = Gpib.Gpib("Network Analizer")
>>> na.clear() # IFC を送る
>>> na.write("*IDN?") # 機器の ID を要求する
>>> na.read() #
'Agilent Technologies,E5071B,MY4230nnnn,A.03.60\n'
>>> na.write(":calc1:mark1:act") # マーカを有効にして
>>> na.write(":calc1:mark1:Y?") # その値を読んでみる
>>> na.read()
'+3.92334286366E-002,+0.00000000000E+000\n' # お、ちゃんと読めた
>>> na.write(":calc1:mark1:X 3GHz") # マーカを移動してみよう。あれ、
>>> na.write(":calc1:mark1:X 3E+9") # そうか、単位は許されないんだ
>>> na.write(":calc1:mark1:Y?") # ここで読んでみると
>>> na.read() # それらしい値になっている
'-1.60429815285E+001,+0.00000000000E+000\n'
# 次は、アンテナの回転台を制御する (そのオブジェクトを作る)
>>> rot=Gpib.Gpib('Rotator')
>>> rot.write("*IDN?") # ID を求めるが
>>> rot.read() # それには対応していないようだ
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "/usr/local/lib/python2.4/site-packages/Gpib.py", line 22, in read
self.res = gpib.read(self.id,len)
gpib.error: Read Error: ibrd() failed
>>> rot.clear() # 応答がなくても、また再開できる
>>> rot.write("TMH") # 回転速度を「高」にして
>>> rot.write("TPX0100") # 位置を 10 度にセットして
>>> rot.write("TPS") # そこへ動かす
>>> rot.write("TCP") # 位置を問い合せる
>>> rot.read()
'0101' # 10.1 と読めた
>>> rot.read() # ただ読むだけではだめ
Traceback (most recent call last):
File "<jstdin>", line 1, in ?
File "/usr/local/lib/python2.4/site-packages/Gpib.py", line 22, in read
self.res = gpib.read(self.id,len)
gpib.error: Read Error: ibrd() failed
とここまでわかれば、後は、回転台を例えば 10
度回すごとに Network Analyzer
で受信レベルを読むというプログラムを書くのは簡単でしょう。
感想他
たとえ NI の Linux サポートが有っても、 C のライブラリを Python から呼べるモジュールにする作業は必要だろうと 「覚悟」していただけに、あっさり Python から呼べる環境が手に入ってとにかく感激です。 まだあまり使い込んではいませんが、感想などを…
- H/W もドライバもかなり安定です。特に、time out
した後、自分自身も相手もハングさせずに、
またコマンドを送り始める事ができるのは良い。
- しかし、測定系の構成を /etc/gpib.conf に言わば hard code
してしまうポリシーはどうなんでしょうか。幸い、そこでの device
の設定はデフォルトで事足りるようなので、
名前をアドレスと同じにして (例えば name = "1" のように)
1 - 31 までエントリを揃えておけば、gpib.conf
を編集しなおさなくても、プログラムで全てを制御できそうな気がします。
- ここからは Python のモジュールに関してですが、まず、 Gpib
モジュールの実装は、やろうとしていた事に近くて嬉しい。
(というか、自分のやってた事が、
そんなに的外れでなかったようで嬉しい、というべきか。)
- SRQ が Python からは扱えない。先々必要になりそうだけど…。
CGI スクリプトと日本語
3/14/04 作成
(*) 10/23/04 改訂
はじめに
#
# 日本語のコメント
def main():
while 1:
name = raw_input("名前を入力して下さい: ")
if name == "bye":
break
print "こんにちは、%s さん" % name
main()
のようなコードを、漢字コードを euc-jp とした(すなわち、オプション
-km euc を付けて起動した)Kterm 上で走らせると、
fukuda@localhost:~% /usr/bin/python ./jap.py 名前を入力して下さい: ソニー こんにちは、ソニー さん 名前を入力して下さい: 松下 こんにちは、松下 さん 名前を入力して下さい:のような感じで、ちゃんと意図どおりに働いてくれます。(/usr/bin/python は Fedora のデフォルトの Python で、2.2.3 です。)まとめると、
- スクリプトの漢字コードを euc-jp にする
- 実行環境 (Kterm) の漢字コードを euc-jp にする
- CGI スクリプトの出力を euc-jp で統一する
そんな「知らぬが仏」的というか「井の中の蛙」的平和の中へ闖入してきたのが Unicode。
まず、Python のデフォルトの encoding が UTF-8 となりました。というか、大部前からそうらしいので、変化と言えば source coding を明示的に指定する事を要求するようになっただけ、と言うべきなのでしょう。 勿論これは素晴らしい事なのでしょうが、 私のような「頑迷固陋」ユーザ にとっては、スクリプトファイルの 2行目に
#!/usr/local/bin/python # -*- coding: euc-jp -*-としておかないと文句を言われるのかぁ、程度のもの (申し訳ありません)。 文句というのは
fukuda@goliath:~% /usr/local/bin/python ./jap.py sys:1: DeprecationWarning: Non-ASCII character '\xc6' in file ./jap.py on line 3, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details 名前を入力して下さい:てな事です。
次に Fedora のデフォルトの日本語環境が UTF-8 に…。しかし XEmacs, Kterm で扱えないんじゃあ意味無い、とばかり、無理矢理 euc-jp に戻した…。 委細は オタク日記を御覧下さい。
あと、それに合わせたのか、Apache-2.x の デフォルトの httpd.conf では、 新たに導入された AddDefaultCharset ディレクティブで、 UTF-8 と設定されている。
それやこれやで、後から辿るのは難しい (恥かしい) ような右往左往が有りました。 ちょこちょこっと直してしまおう、 という料簡が事態をますます悪くしているのは解っているのですが…。
Python-2.3 では…
などと前置きを書いてきたところで、PyJUG のサイトに Python-2.3 での日本語使用について、要領良く纏められたアーティクル("Python と日本語")が上がっている事を発見。(今更…:-)。Python そのものについては、そちらを御覧下さい。 そのうちで、スクリプトを書くにあたって関係ありそうなのは- デフォルトの encoding を例えば euc-jp
にしておくと、すなわち、site.py で
encoding = "japanese.euc-jp"
としておくと、euc-jp で書かれたスクリプトの中では、unicode の文字列を書くのにustring = u"これは例です"
とできる。(以前は、ustr = unicode("これは例です", "euc-jp") 等とする必要が有ったと思う。)(*) Python-2.4 では、encoding = "euc-jp"
としないとダメみたいです。下記参照 - スクリプトの coding を指定するのに、
# coding: euc-jp
もしくは# coding = euc-jp
とすれば良い。実は、現在でも(Python-2.3 でも)# -*- coding: euc-jp -*-
としなければならい、と思い込んでいて、シンプルさを身上とする Python にしては「なんだかなぁ」と感じていたのでした。 - いちいち、codecs を別途インストールするのも「なんだかなぁ」
でしたが、これも Python-2.4 からは、CJKCodecs
が最初から入るようです。Nice!!
(*) 予告通り 2.4 には CJKCodecs が統合されました。
現在の設定
という事で、ひとつの例として My Home Server での例を挙げようと思っていたのですが、急遽一部変更をする事に…。 なのでちょっと検証が足りないところもあるかも知れませんが、まあ、 大目に見て下さい。大目標というか方針は、
- httpd (Apache) が送り出すコンテンツは iso-2022-jp
を使う事に統一する。(euc-jp
でも良いかも知れませんが、iso の方が、Windose
のブラウザで文字化けする確率が低いような…)
- 従って、html ファイルは、iso-2022-jp で書き、
- CGI スクリプトについては、本体は euc-jp で書くが、出力は明示的に iso-2022-jp でエンコードする。
と思い込んでいたのですが、 今ちょこちょこっと試してみた範囲では、そうでもないようです。
で具体的な設定ですが、
Python:
- JapanseCodecs をインストールする。最新版は、
JapaneseCodecs-1.4.10 で、
PyJUG サイトにあります。展開して、そのトップディレクトリで
# python setup install とするだけ。
(*) Python-2.4 では必要ありません。
- /usr/local/lib/site.py で
encoding = "japanese.euc-jp"
と変更する。(Python の追っかけをやっていると、アップデートの際にこの変更を時々忘れます。 環境変数で定義できるようにするとか、できないものですかね。)(*) Python-2.4 では、
encoding = "euc-jp"
とする。"japanese.euc-jp" としたのでは site.py が include できなくなって、python が全く走らなくなってしまう。
- コーディングを iso-2022-jp に。
- ファイルの <head> に
<meta http-equiv="Content-Type" content="text/html; charset=euc-jp">
という記述を入れて、明示的に iso-2022-jp を指定する
- コーディングを euc-jp に。
- 1行目か 2行目に
# coding: euc-jp
という指定を入れる。XEmacs ユーザは# -*- coding: euc-jp -*-
としておくと、コードの自動判別がより正確になるようです。 - リテラルは、
foostr = u"E-mail アドレスを入力"
のように、全て Unicode にしておく。こうする事で、「書式指定」や 正規表現等がキチンと動く。 - これを (httpd 越しに) 出力する際は、
print foostr.encode("iso-2022-jp")とする。(*) "japanese.iso-2022-jp" としない。- (*) 入力は、例えば、file から euc-jp の euc_string を読み込んだとすると、
utf_string = unicode(euc_string, "euc-jp")
として、明示的に euc_string を unicode に変換しておく。- (*) ただ、明示的にこれをやらなくても、うまく行く場合もある。
- site.py で encoding = "ascii" のままの場合、string が JIS
code (iso-2022-jp) で有れば、unicode()
による変換をしなくても u"this is %s" % string
等に際して起きる implicit な unicode への変換はうまく行く。
しかし EUC の string は、このような場合
UnicodeDecodeError となる。
- site.py で encoding = "euc-jp" としておけば、JIS の
string も EUC の string も、implicit な unicode
への変換がうまく行く。
- POST などによって、CGI が <FORM> の TEXT INPUT から受けとる string のコーディングは、<FORM> を含む HTML file のコーディングで決まる。 (ように思えますが、まだよく検証できていない。)
- (*) 入力は、例えば、file から euc-jp の euc_string を読み込んだとすると、
(3/20/04 (Sat) 追記) HTML ファイルのエンコーディングを iso-2022-jp にしたので、Fedora に附属の less では見えなくなってしまいました。XEmacs で扱えたら実害は無いのですが、癪なので less-358-iso258 をインストールしました。(-> 最近の Update/Install)
数値計算とプロット
能書き
Python + Numeric + Gnuplot という環境をしばらく使ってみて、私はとっても感動してしまいました。 この感動を他の人にも伝えたい、との思いでこれを書いています。 しかしながら、 数値計算も、その結果のプロットも(多分 Python そのものも) 私は良く知らないので、その思いがどれくらい伝わっているか、 ちょっと心許無い気もしています。
手始めに
実際に Python を立ちあげて、sample session ? をやってみましょう。
fukuda@goliath:~% python Python 2.2.1 (#1, Apr 10 2002, 23:15:58) [GCC 2.96 20000731 (Red Hat Linux 7.1 2.96-98)] on linux2 Type "help", "copyright", "credits" or "license" for more information. # Numeric (NumPy), FFT モジュールをインポート >>> from Numeric import * >>> from FFT import fft # Gnuplot のラッパ Gplot をインポート >>> import Gplot as G # 時間軸と周波数軸の定義 >>> t = arange(0.0, 4.0, 1.0/16) # 0 から 4 まで 1/16 きざみ >>> f = arange(0.0, 16.0, 1.0/4.0) # サンプルとして v(t) = cos(2πfot) を定義する。 >>> v = cos(2.0*pi*1.5*t) # これをプロットしてみましょう。 >>> g = G.Gplot() >>> g.plot2(t, v) # このコマンドでこのようなグラフが pop up します。(click で拡大画像)
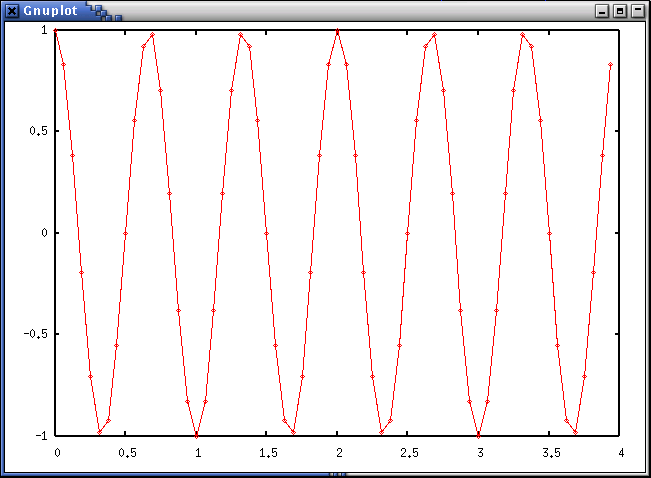
# この関数 v(t) の Fourier 変換 V(f) を求めます。 >>> V = fft(v) # この V(f) の plot です。(V(f) は複素数だから、絶対値に直して表示) >>> g.plot2(f, abs(V))
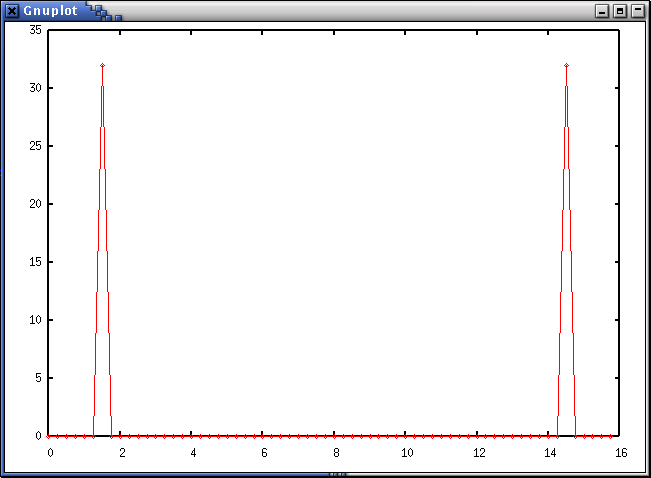
以上で、途中の関数のグラフで確認しながら、サンプルの関数を定義し、 それを FFT した訳ですが、驚く程簡単でした。 ちょっと「感動もの」だと思いますが、いかがでしょうか。
しかし私には、 この「簡便」という事よりスクリプトがとても「直観的」 になる事の方がうれしい。例えば、
v = cos(2.0*pi*1.5*t)と定義すれば、それ以降、 普通の数式を扱うようにこのオブジェクトを扱える訳です。(代入する、 プロットする等。)まあ、v を v(t) と書けたり、cos(2π1.5t) なんて書けたらもっと良いんでしょうが、それは欲張りすぎ?
これは、Numeric というモジュール内の数学関数が、 「配列を引数に取り、また配列を戻り値として返す」 という設計になっている事のおかげです。arange で定義されている t や f は実際は一次元配列になっている訳。 また、それを引数として計算される v も実は一次元配列。 またこれから、V = fft(v) というたった一行で、その Fourier 変換 V が得られた、という訳です。
この事の効果は絶大で、論文を読む時、数式を visiualize しながら… とか、数式の導出を、シミュレーションで確かめながら(邪道か?) などという場合に、とても見通しが良くなります。
環境整備
さて、「感動」を共有していただけたでしょうか。 しかしながら、 これらのモジュールを使う為には、大抵の場合 新たにインストールする必要があります。
Python
大抵の Linux ディストリビューションには Python が標準で入ってる筈ですが、この際、最新版にしておきましょう。 (古い版はそのまま残しておきます。)現時点(6/8/02) での最新版は 2.2.1 です。 sourceforge から取って来れます。インストールは、 ソースを展開したディレクトリで$ ./configure $ make # make installとするだけです。
Numeric (NumPy)
これも最近新しくなりました。 sourceforge から Numeric-21.0.tar.gz を取ってきます。(7/7/02 改訂: 今日の時点での最新版は、21.3)こちらのインストールは、 もっと簡単で、# python setup.py installとするだけ。
Gnuplot
Gnuplot は gnuplot の wrapper なので gnuplot が必要です。 これも大抵のディストリビューションにはデフォルト でインストールされていると思います。 しかし、新たにインストールするのであれば、最近出た最新版(-3.7.2) にしましょう。 sourceforgeのソースを、./configure ⇒ make ⇒ make install するだけ。Gnuplot.py の方は、ここ一年以上バージョンアップされてなくて、 -1.5 のままです。これも sourceforgeから取ってきます。 (改訂されて、 gnuplot-py-1.6 となりました。9/1/02 (Sun)) これも、他の Python のモジュールと同様、
# python setup.py installとするだけで、インストールできます。
Gplot
Gnuplot でも十分使い易いのですが、gnuplot の汎用性をあまり損ねないようにという配慮のせいか、 「とにかく手軽に数式のグラフを書きたい」という用途には、 それでもまだ煩わしい事があります。(Data オブジェクトを定義する必要が有る等。)そこでもう一枚、ラッパーと言うのもおこがましいような薄い wrapper を作ってみました。Gplot.py という module の中身は、単に
import Gnuplot
class Gplot(Gnuplot.Gnuplot):
def plot2(self, x, y, style="linespoints"):
self.plot(Gnuplot.Data(x, y, with=style))
def plot1(self, x, style="linespoints"):
self.plot(Gnuplot.Data(x[0], x[1], with=style))
というだけものです。plot1() はこの後説明します。これを、
/usr/local/lib/python-2.2/site-packages か、python
を起動するディレクトリに置きます。
応用例-1(確率分布の確認)
さて、「式は導出したみたものの、今一自信が無いなぁ」なんて時、 ちょこちょこっとシミュレーションしてみると、 手っとりばやく確認できる事があります。 確率分布などは、その好例でしょう。 (という事で、この節には、あまり見慣れない確率統計の用語が出てきますが、 それ自体はさほど重要ではないので、さらりと流して下さい。)
おぼつかなく式を導く
さて、ディジタル通信の世界では、データ伝送の確かさを BER (Bit Error Rate) で計ります(10,000 bits 送って 1 bit 間違えるなら、BER = 1.0e-4 であると言う)。その測定で表われる Error が互いに独立に生起するとすると、その間隔 t は指数分布に従います。
このような Error を観測して m 番目の Error が発生する時刻 t も確率変数となり、その確率分布は、m-Erlang 分布となります。 あまり聞きなれない分布ですが、幸いこれは良く知られたカイ自乗分布 (chi_square_cdf)で表わされ
m-Erlang_cdf(t, R) = chi_square_cdf(2Rt, 2m) (1)
m-Erlang_pdf(t, R) = 2R*chi_square_pdf(2Rt, 2m) (2)
ここに R は Error の平均頻度。
ここまでは、教科書にも書いてある事柄なので、まあ確実なのですが、 この式から、error rate の分布を導く、というのが今回の課題です。 m 個の Error を観測するのに t 秒かかったとすれば、error rate r は、r = m/t。この確率変数の CDF, pdfは、
CDF(r) = 1.0 - m-Erlang_cdf(m/r, R)
= 1.0 - chi_square.cdf(2(R/r)m, 2m) (3)
pdf(r) = 2mR/(r*r)chi_square.pdf(2(R/r)m, 2m) (4)
chi_square.py というモジュールに、カイ自乗分布の pdf と CDF の定義を関数として書いておくと
>>> import chi_square >>> from Numeric import * >>> import Gplot >>> g=Gplot.Gplot() >>> R=1.0 >>> m=3 >>> r=arange(0.05, 5.0, 0.05) >>> g.plot2(r, 2.0*m*R/(r*r)*chi_square.pdf(2.0*(R/r)*m, 2*m))とする事で、次のようなプロットが得られます。(chi_square.pdf() は、chi_square というモジュールの中の pdf という関数を表わす。)
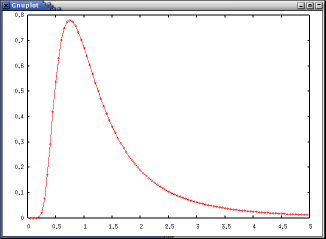
パラメータをちょっと変えて、プロットしたい、(例えば、m = 10 としたらどうなるか)という場合は
>>> m=10 >>> g.plot2(r,2.0*m*R/(r*r)*chi_square.pdf(2.0*(R/r)*m, 2*m))などとするだけ。
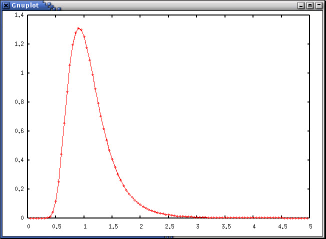
さらに、r についての分布ではなく、t についての分布(すなわち m-Erlang 分布)が、m = 1 の時に指数分布になるはず、という事も、次のように確かめられます。
>>> m=1 >>> t=r >>> g.plot2(t, 2.0*R*chi_square.pdf(2.0*R*t, 2*m))
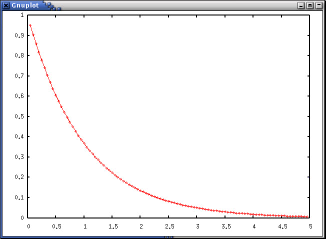
確率分布を実際に求めてみる
さて、一応は式が導出されたし、それをプロットしてみたら、 それらしい格好をしている。でも、そこは素人の悲しさ、自信をもって「これで OK」と言いきれない。 で、本当に確率変数を生成してみて、それがどうなるか見てみよう、 という訳です。
幸い、Python の Numeric パッケージには、RandomArray というモジュールが有り、これには指数分布を発生する exponential という関数が入ってます。 これが生成する確率変数の値(t1, t2, t3...) を m 個集めて、それから r = m/(t1 + t2 + ... tm) とすれば、 error rate の(ひとつの)観測値が得られるわけです。これを Python で書くと、
import RandomArray as RA
def BER(r=1.0, n=200):
# exponential(mean_value, numbre_of_data)
# returns array of n generated values
time = RA.exponential(1.0/r, n)
t = 0.0
ber = []
for i in xrange(n):
t = t + time[i]
ber.append((i + 1.0)/t)
return ber
def dist(m=10000, r=1.0, n=200):
err_rate = []
for i in xrange(m):
ber = BER(r, n)
err_rate.append(ber[-1])
return err_rate
まあ、これくらいは、インタラクティブにやっても良いのですが、
(実際最初に試した時はそうしたんですが)先々繰り返し使いそうなので、
スクリプトにしました。これを、例えば、ber.py
にセーブしてモジュールとして使います。(もうひとつの
モジュール (mymath.py)は、
雑多なツールを集めたものです。)
>>> import ber
>>> import mymath
>>> import Gplot as G
>>> g=G.Gplot()
>>> err_rate = ber.dist(m=100000, n=10)
>>> g.plot1(mymath.histo(err_rate, min=0.0, max =5.0, nstep=50))
ここで、plot1() を使ました。(関数は tuple
として、例えばヒストグラムの刻みと頻度の組み合わせを返す事ができますが、
これはあくまで一つのオブジェクトであり、
二つの引数を取る関数へ直接代入できません。)
下のようなグラフが得られます。
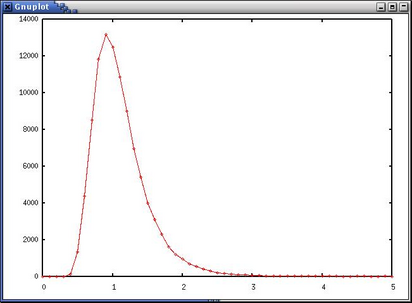
これでも十分それらしいですが、もっとよく見てみましょう。 まず、この histogram を正規化して、pdf と直接比べられるようにします。( histo2pdf() を使う。)また Gplot では(まだ)グラフの重ね打ちができないので、Gnuplot に戻ります。err_rate には、先のシミュレーションの結果が入っているとします。
>>> import Gnuplot as G >>> (histx, pdf) = mymath.histo2pdf(mymath.histo(err_rate, min=0.0, \ ... max =5.0, nstep=50)) >>> dhisto = G.Data(histx, pdf, with="points", title="Simulation") >>> dtheory = G.Data(r, 2.0*m*R/(r*r)*chi_square.pdf(2.0*(R/r)*m, 2*m), \ ... with="lines", title="Theory") >>> g.plot(dhisto, dtheory)
このように二つのプロットを合せてみると、 ぴったり一致している事が判ります。(ドットが、 シミュレーションの結果をヒストグラムにして正規化したもの、 線が、導いた式をプロットしたもの、です。)
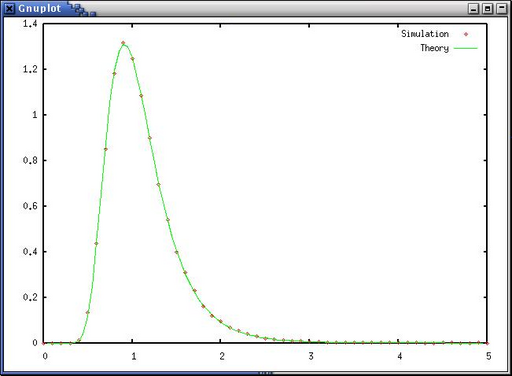
Gnuplot を呼び出したので、 ついでにレポートに載せれる程度に表示に凝ってみます。
>>> g('set key title "m = 10, R = 1.0"')
>>> g('set xlabel "Error Rate"')
>>> g('set ylabel "pdf, histogram"')
>>> g('set format x "%02.1f"')
>>> g('set format y "%02.1f"')
>>> g.replot()
>>> g('set term png color')
>>> g.hardcopy("pdf_m10_r1.png")
こうやると、
pdf_m10_r1.png というファイルにハードコピーがセーブされます。
そう、それで?
以上で、おぼつかない手付で導いた式が、どうやら正しい事が示せました。 全然違う方法で求めた確率分布が、このようにぴったり合うと快感です。
しかしまあ最初の能書きで期待させた程にはにはすっきりしていないかも。 しかも、ここに上げたのは、道筋を示すためのほんの一部にすぎず、 ほんとはこんなにスッキリ行かない。「だったら、なにが嬉しいの」 と言われそうですが、むしろ強調したいのは、この環境 (Python + Numeric + Gnuplot) は、このような試行錯誤の際にこそ大きな力を発揮するという事です。 「だったら、その例を示さんかい」ですが、 それはそのうちに…。
 18/1,926,628
Taka Fukuda
Last modified: 2010-03-27 (Sat) 17:56:46 PDT
18/1,926,628
Taka Fukuda
Last modified: 2010-03-27 (Sat) 17:56:46 PDT